Données en ordre
Notebook interactif: ![]()
Que partagent un bon cuisinier et un bon “data analyst” ? La préparation avant la recette.
Pour un chef, la clarté vient de l’organisation de son espace. Les quelques ustensiles nécessaires sont à portée de main et les ingrédients sont positionnés stratégiquement.
C’est un concept que l’on retrouve en analyse de donnée sous le nom de “tidy data”, un terme popularisé par Hadley Wickham, dans un article du journal of statistical software.
L’essence des propositions de Hadley tourne autour de 3 axes:
- Une ligne est une observation

- Chaque colonne est une variable
- Une cellule contient une valeur unique

Etude de cas
La question qui va nous guider pour cet exemple:
“Quel est l’âge approximatif des habitants de Lille, Strasbourg et Paris en 2018” ?
L’insee offre de nombreux jeux de données démographiques
Chaque année, l’Insee estime la population des régions et des départements (France métropolitaine et DOM) à la date du 1ᵉʳ janvier. Ces estimations annuelles de population sont déclinées par sexe et par âge (quinquennal, classes d’âge).
note: c’est souvent une bonne idée de parcourir la documentation de la donnée
Le dataset est un fichier excel :
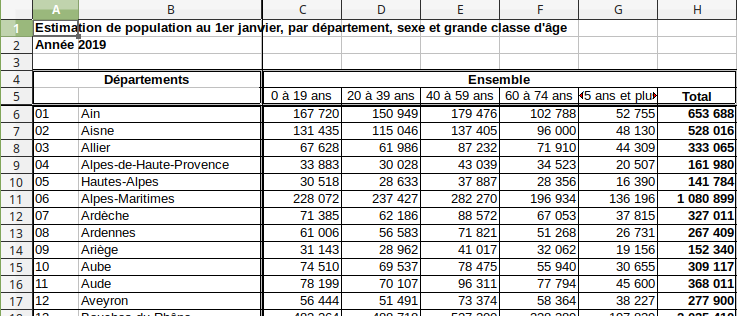
Je vous passe les détails de la transformation en csv qui nous amène à ce résultat.
| departements | 0 à 19 ans | 20 à 39 ans | 40 à 59 ans | 60 à 74 ans | 75 ans et plus |
|---|---|---|---|---|---|
| 01 | 167720.0 | 150949.0 | 179476.0 | 102788.0 | 52755.0 |
| 02 | 131435.0 | 115046.0 | 137405.0 | 96000.0 | 48130.0 |
| 03 | 67628.0 | 61986.0 | 87232.0 | 71910.0 | 44309.0 |
| 04 | 33883.0 | 30028.0 | 43039.0 | 34523.0 | 20507.0 |
| 05 | 30518.0 | 28633.0 | 37887.0 | 28356.0 | 16390.0 |
Chaque colonne est une variable
Les variables sont :
- Le département
- L’age
- Le nombre de personne
On s’attends à trouver 3 colonnes, mais on en a ici beaucoup plus.
Les colonnes 0 à 19 ans, 20 à 39 ans, … sont en réalité les valeurs de la variable age.
Comment passer la donnée en tidy ?
0n transforme les colonnes en lignes (les outils emploient souvent les termes de melt ou stack)
| departements | tranche | nb |
|---|---|---|
| 82 | 0 à 19 ans | 63113 |
| 08 | 60 à 74 ans | 51268 |
| 51 | 75 ans et plus | 49020 |
| 03 | 60 à 74 ans | 71910 |
| 04 | 40 à 59 ans | 43039 |
| 81 | 0 à 19 ans | 85209 |
| 80 | 75 ans et plus | 50518 |
| 03 | 0 à 19 ans | 67628 |
| 93 | 40 à 59 ans | 423665 |
| 03 | 75 ans et plus | 44309 |
Cette disposition permet de répondre à notre question sans se battre avec son outil.
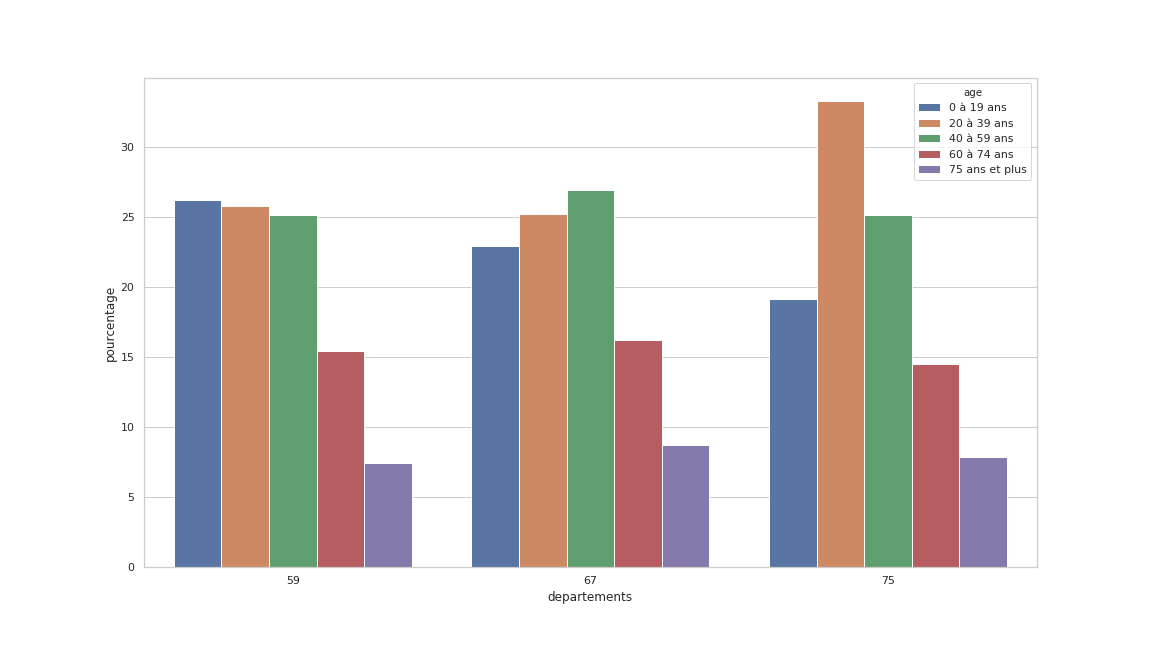
“Quelle est l’age approximatif des habitants de Lille, Strasbourg et Paris en 2018”
En python cela donne :
"""
Behind the scene :
1.`france` est de type Pandas dataframe
1. on normalise en pourcentage les valeurs pour comparer les départements
pourcentage = (nb tranche d'age pour un departement) / (nombre total de personne dans un departement)
"""
france[france.departements.isin(['59', '75', '67'])]
ax = sns.barplot(x="departements",
y="pourcentage",
hue="tranche", data=france)
plt.show()
So what ?
Moins de temps passé à discuter avec son outil == plus de temps pour la réflexion et l’interprétation des résultats.
J’ai l’habitude de faire mes analyses avec la pydata stack mais un excel ninja devrait pouvoir appliquer les transformations utilisées ici sans trop de problèmes et en tirer les mêmes bénéfices.
Pour aller plus loin, l’article de Hadley Wickham donne plusieurs solutions pratiques pour convertir un dataset dirty en tidy.